CSE 423 Compilers
Alexander Benson
Jacob Garcia
Ole Jeger Hoffstuen
Keaton Jones
Expand source code
import os
import sys
# sys.path.insert(0, os.path.dirname(__file__))
sys.path.append(os.path.dirname(__file__))-
Design Document
-
-
Introduction
- We are tasked with creating a compiler for a subset of the C programming language. With this challenge includes figuring out how to implement the three fundamental parts of any compiler: Frontend, Optimization, and the Backend. Our goal with this project is not only to design and implement an optimizing compiler, but to strengthen our ability to design and create software that achieves its purpose and provides adequate documentation to explain how it operates.
-
Language / Libraries / References
-
- Python 3.7+
- Rply , Python's re-implimentation of Lex-and-Yacc
- Pdoc3 , used for documentation
- Inspiration for pretty printing the tree
- Inspiration for how to deal with logical not at the assembly stage
-
Architecture
- Our compiler can be split into three major stages that takes in a C program and converts this "High-Level" language into many different forms of Intermediate Representations (IR's) until it reaches the point of assembly code. Our compiler compiles to GAS syntax amd64 assembly, and uses x86-64 calling conventions.
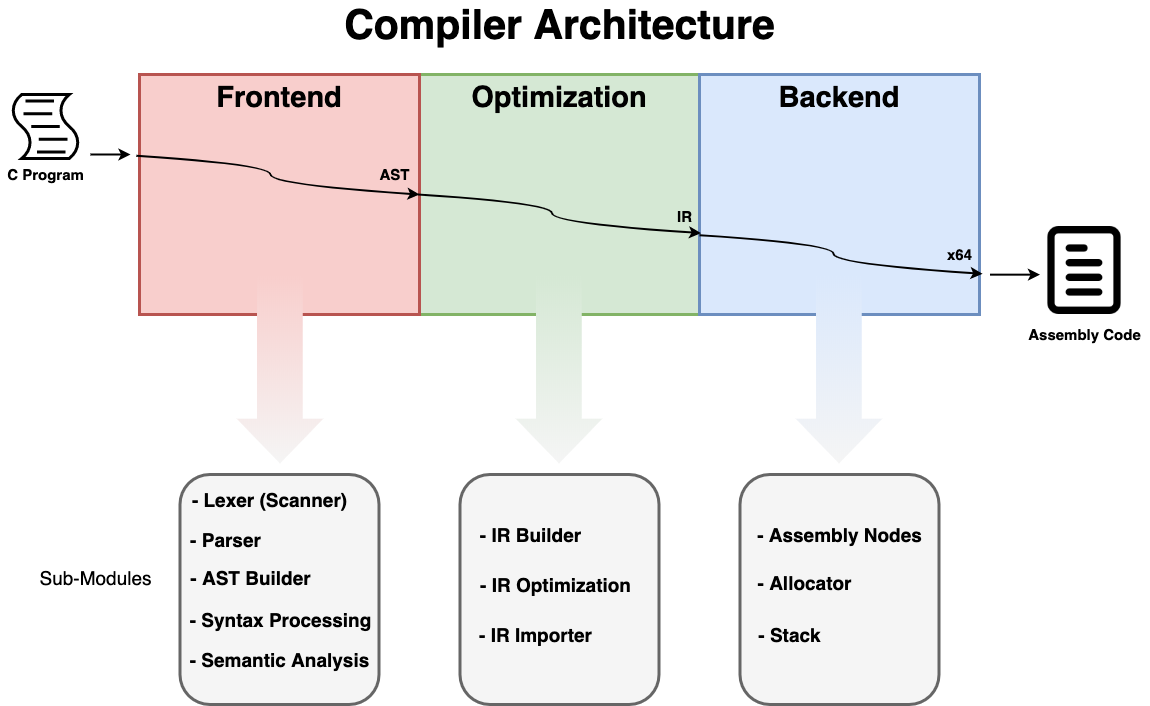
-
Frontend
-
-
Lexer
-
Responsible for scanning and assigning tokens to
different elements of our C program, this module was
designed using RPLY's lexer class. By simply adding in
tokens to our lexer we are able to give it a string version
of our C program and get a list of all valid tokens.
-
Token Format / Examples
-
Token("TOKEN_NAME", "ELEMENT") Token("INTEGER", "1") Token("GT", ">") Token("SELF_DEFINED", "some-variable-name") Token("AND", "&&") Token("ACCESS", "->") -
Error Handling
-
Currently the only known errors we can experience
while using RPLY's lexer library is when we encounter
an element that isn't recognized. By adding an
INVALIDtoken type, and having it match to any string combination, we eliminate the possibility of the imported lexer code to fail, and are able to report any invalid tokens to the user.
-
-
Parser
-
This sub-module relies on RPLY's parser generator but still
requires a grammar. After defining a grammar in a separate
file we can construct a parser using RPLY syntax that will
take in the grammar and build our Parse Tree. Currently RPLY
has allowed us to impliment a "Bottom-up left-to-right" parser.
-
Example of BNF grammar
-
program : definitionList #program definitionList : definition_terminal definitionList #definitionList definitionList : definition_terminal #definitionList definition_terminal : functionDefinition #definition_terminal definition_terminal : functionDeclaration #definition_terminal definition_terminal : initialization #definition_terminal definition_terminal : COMMENT #definition_terminal functionDefinition : func_type SELF_DEFINED OPEN_PAREN args CLOSE_PAREN block #function definition functionDefinition : func_type SELF_DEFINED OPEN_PAREN CLOSE_PAREN block #function definition functionDeclaration : func_type SELF_DEFINED OPEN_PAREN args CLOSE_PAREN SEMICOLON #functionDeclaration functionDeclaration : func_type SELF_DEFINED OPEN_PAREN CLOSE_PAREN SEMICOLON #functionDeclaration func_type : TYPE #func_type func_type : func_modif TYPE #func_type ...Our Full BNFTODO:
- We are only reporting the last successful token parsed but not giving a detailed and more "useful" message.
-
-
Abstract Syntax Tree Builder
-
Using the initial Parse Tree, we are able to shorten it down and "abstract" it to have
a more understandable and syntax-free way to represent a C program. We currently have a single
function,
buildAST(parseTreeHead), that constructs a series ofASTNodeobjects with references to each other. Represented in the correct way, this creates a "Tree" data type.-
Representing a Program
-
Every AST produced by our compiler will start with
programdenoting the root of the C program. Following this root, there could be a series of function prototypes,decl, and function declarations,func. Whether it be a prototype or declaration there will always be 3 branches that describe the Type, Function-Name, and Function-Parameters. In the case of a declaration, an extra node markedbodywill link to the actual body of the function. Other keywords such asvar(variables),call(function calls), and arithmetic operations (+, -, *, /, etc.) exist in the produced AST if such content exists in the original C program. - Example AST representations can be found under: Examples of C Programs and their Intermediate Representations .
-
-
Semantic Analysis
-
Our semantic analysis include checks for Undeclared functions/variables,
type mismatch (for the possibility of types other than Int),
correct number/types of function parameters.
NOTE: There is a possibility of more stages of semantic analysis being implimented in the future, but it would be a supplemental feature for this project.
-
Symbol Table
-
By constructing a symbol table using our AST, it becomes a lot easier to perform analysis on the C program.
This table contains properties such as:
- Name
- Entry type ie. function, variable, label, etc.
- Type ie. int, double, float, etc.
- Scope
- References in the program
- Modifiers (if any)
- Example symbol tables can be found under: Examples of C Programs and their Intermediate Representations .
-
-
-
Optimization
-
-
Intermediate Representations
-
For our IR, we decided to closely mimic Gimple, the IR used by GCC. In designing it, we aimed to keep as close as possible, but with the design decisions that made out lives easier in the long run. The basis of our optimization compenent of the compiler is converting one IR, the abstract syntax tree, to another, linear, IR. The resultant IR is then used to construct the assembly code in the Backend. The compiler as a whole allows for a few methods of interaction that all result in the linear IR. Building it from the AST and the symbol table or importing it through the commandline. In addition to this, the compiler does allow for a flag to specify the level of optimization that will be performed on the input.
-
IR structure
-
The linear IR is structured in a way that all we have to do is to interact with the concept of a singular hypothetical line in the IR. This line may or may not boil down to multiple sub-lines called
IRNode. EachIRNodewould represent close to one assembly instruction with a few exception. This allows us to generalize over the IR as a whole when it comes to converting it to assembly. The design decision to have different IR instructions as their individual data type (that inherit from same parent class), was to have a way of storing these instructions not as a String yet still having a way to be converted to a String for visual representation. The types of nodes that we have defined goes as follows:- IRJump
-
This node represents a label for a goto statement in the IR, for instance it’s string representation:
label: - IRGoto
-
This node represents a goto statement in the IR, for instance it’s string representation:
goto label; - IRIf
-
This node represents an if statement in the IR, for instance it’s string representation:
if(a == b) goto <D.1234>; else goto <D.1235>;NOTE: If the condition contains conjunctive and disjunctive operations, the expression will be split up into its subsequent parts and consider the termination conditions that can be assumed through short circuiting. As such we also implement short circuiting at a higher level rather than having to deal with it at some other point.
- IRArth
-
This node represents arithmetic in the IR, for instance it’s string representation:
i = 15 + 25;NOTE: Expressions that consist of multiple operations will result in a sequence of singular binary operations that will respect the order of operations as well as the results from each respective operation. This will result in multiple
IRNodeobjects which each takes care of a singular operation. - IRSpecial
-
This node represents “special” operations like incrementation and decrementation in the IR. Depending on whether it is a pre or post operation, the linear IR preserves the value in a tempoary variable so that the result stays true to that of the C language. If it is a post-incrementation, this is the IR produced:
_0 = i; i = i + 1; - IRAssignment
-
This node represents variable assignment in the IR, for instance it’s string representation:
x = 25; - IRFunctionAssign
-
This node represents a variable being assigned to the output of a function, for instance it’s string representation:
Just as a note, all function calls in our IR are represented this way, even functions which do not return or return null are given a variable they “return” to.x = sampleFunction(1, 2); - IRFunctionDecl
-
This node represents declaration of function, and the body is defined after this IR node. For instance it’s string
representation:
main (int a, int b)NOTE: Following this
IRLineobject, there will be an IRBracket object which represents the start of a scope. - IRReturn
-
This object handles return statements. Returns can return nothing or a value. for instance it’s string representation:
return D.1235; - IRBracket
-
This object just holds either an opening or closing bracket. for instance it’s string representation:
{or} - IRVariableInit
-
This object handles lines of the IR involving variable initialization. for instance it’s string representation:
int a;NOTE: Variable initializations are made for every variable and they cannot be done inline with assignment. When the inputted C program does this in one line, it is split up in our IR.
-
Building an IR (from AST and Symbol Table)
-
In order to derive a linear IR from the AST and symbol table, we instantiate several
IRLineobjects which each represents some required part of the program, and individually breaks down into lower level instructions/operations than what is presented to the user in the AST. Each of these smaller building blocks can be seen above. There are cases where eachIRLineonly contains a singular building block, but in those cases there are special circumstances that require that to happen such as closing and opening of scopes through the use of theIRBracketclass. -
Importing an IR
- The importing of an IR works very much like how the lexing and parsing of a C file. We designed our own grammar and convert the output to the same format as something that was built through the use of a valid C file. This allows us to perform the same optimizations on the imported IR as the IR that is generated from a C file.
-
Optimizing an IR
-
As a group we decided to implement four different optimization mechanisms as a part of three total optimization
levels.
-O0means that no optimization occurs during the compilation process.-O1means that there are slight optimizations done during the compilation process.-O2means that there are more advanced optimizations done during the compilaion process. Keep in mind that they are by no means agressive, and there is no risk of altered behavior of the program when using these optimizations.
The following are the different optimizations that we support:-
Removing Unreferenced Variables
Removing Unreferenced Functions
Constant Folding
Constant Propagation
IR Cleanup
-
Removing Unreferenced Variables
-
-
-
Backend
-
-
Assembly Generation
-
Since our IR was converted to a series of nodes that represent each IR line type we expect, we can leverage that same IRNode class in order to generate our initial assembly. This initial assembly still uses variable names instead of registers, and we then do proper register allocation in the next "phase".
Each IRNode class has a corresponding function, called "asm", that uses the built IRNode that has already been built in our previous optimization step, and uses the information stored in it to convert it to an assembly representation.
In these "asm" functions we build a list of ASMNodes, another class we have defined, and return that list of ASMNodes. Then, we call the asm function on each IRNode that is produced via our optimization step, and append the list that each asm function returns to a master list. This master list is then passed into a class called allocator, that does register allocation.
-
ASMNode
- The ASMNode class creates an object with a series of variables that determine important information for the register allocation step. The class expects an op, left, right and a kwargs dictionary. A series of useful flags are passed in as the dictionary kwargs to the initialization of an ASMNode, and then the initializaiton goes through this dictionary to set the appropriate flags for the new ASMNode. It stores most instructions in the general form of "op left, right", and for some nodes the left and right can be none. Some examples of flags om the class include "leftNeedsReg", which indicates that in register allocation we will need to allocate a register for the left operand of the given ASMNode, and the flag "leftIsLiteral", which indicates that the left operand of the ASMNode is a literal (i.e $4). (There are various other flags, thesea are just two examples.)
-
-
Register Allocation
- The register allocation step uses a class called "allocator" in order to go through a list of ASMNodes that is passed in, and then modify their left and right operands to be replaced by the appropriate registers where necessary. In order to do this, it separates the different scenarios where different register allocations need to be done by making a series of "cases", each of which is determined by the flags set in the ASMNode class. Then, in these cases it uses a class that represents a directory of registers, and a registerData class to determime what registers are open, and what is in those registers at what given time. As well as this, we implemented a stack class, which is used to mimic the stack in x64 assembly, and move things on, off, and determine what is where in the stack. Finally, after register allocation, the class returns a new list of ASMNodes, with some new additions that are necessary for the register allocation, and the variables in the initial list changed to the appropriate registers. We attempt to follow an optimal register allocation algorithm, with some strange (but functioning) results sometimes.
-
-
-
Instruction Set
-
-
Assignment Instructions
-
- mov
- pop
- push
-
Arithmetic and Bitwise Instruction
-
- add
- sub
- imul
- idiv
- sar
- sal
- not
- or
- and
- xor
- neg
- inc
- dec
-
Control Flow
-
- jne
- je
- jle
- jge
- jl
- jg
- test
- sete
- cmp
-
Misc Instructions
-
- jmp
- ret
- call
-
-
-
-
User Manual
-
-
How to use the compiler
-
The compiler is split up into three modules, the frontend, the optimizer, and the backend. So far only the frontend is implemented, but there are two alternatives for how to execute the compiler.
run.pyis located in./srcand provides the interface to the whole compiler. However if you desire to run the frontend by itself you can execute the filefrontend.pylocated in./src/frontend. Onlyrun.pywill accept the following arguments, the rest belong to their respective sections:-
-h - Displays the help message.
-
--all - Prints out all intermediate representations as they are encountered in the compilation process.
-
-lor--lex - Prints out the tokens produced by the lexer in a list.
-
-tor--tree - Prints a list like tree structure of the tokens after they have been parsed.
-
-por--pretty - Prints a tree structure of the tokens after they have been parsed.
-
-astor--ast - Prints out the abstract syntax tree.
-
-sor--symbol_table - Prints out the known and unknown symbols encountered during semantic analysis.
-
-eor--errors - Prints out the errors in the semantic analysis.
-
-ir - Output the first level of IR in the optimizer phase.
-
-b[INPUT FILE]or--bnf[INPUT FILE] -
Allows for rebuilding of BNF grammar and parser before the frontend touches the input.
[INPUT FILE]defaults to the fileBNF_defintionlocated in./src/frontend. The BNF grammar is not updated unless this option is provided -
-i[INPUT FILE]or--input[INPUT FILE] - Used to input IR from file. Optimizations will be applied if the optimization flag is passed in.
-
--IRout[OUTPUT FILE] - Ouput the final optimized IR to a file. Filename must be given.
-
-asmor--asm - Display the Assembly that is generated
-
--ASMOut[OUTPUT FILE] - Outut the generated Assembly to a file
-
-
Subset of C supported
-
The plan is to support the whole set of C instructions for as much of the compilation process as possible. As such here is a table of what parts of the compiler supports what features:
Feature Preprocessor Lexer Parser AST Building Semantic Analysis Intermediate Representation Assembly Generation 1: With and without arguments/parameters.
2: With a specific scope and with only one line following it.
3: Both pre and post operators.
4: Bothlong long intandlong longare accepted.
5: Only local header files currently due to platform interaction.
Declaration, Definition, and Calling Declaring Variables − ✓ ✓ ✓ ✓ ✓ ✓ Assigning Variables − ✓ ✓ ✓ ✓ ✓ ✓ Declaring Functions [1] − ✓ ✓ ✓ ✓ ✓ ✓ Defining Functions [1] − ✓ ✓ ✓ ✓ ✓ ✓ Calling Functions [1] − ✓ ✓ ✓ ✓ ✓ ✓ Assignment =− ✓ ✓ ✓ ✓ ✓ ✓ +=− ✓ ✓ ✓ ✓ ✓ ✓ -=− ✓ ✓ ✓ ✓ ✓ ✓ *=− ✓ ✓ ✓ ✓ ✓ ✓ /=− ✓ ✓ ✓ ✓ ✓ ✓ %=− ✓ ✓ ✓ … ✓ ✓ <<=− ✓ ✓ ✓ … ✓ ✓ >>=− ✓ ✓ ✓ … ✓ ✓ |=− ✓ ✓ ✓ ✓ ✓ ✓ &=− ✓ ✓ ✓ ✓ ✓ ✓ ^=− ✓ ✓ ✓ ✓ ✓ ✓ Keywords sizeof− ✓ ✕ ✕ ✕ ✕ ✕ typedef− ✓ ✕ ✕ ✕ ✕ ✕ inline− ✓ ✓ ✓ … ✓ ✕ register− ✓ ✓ ✓ … ✓ ✕ volatile− ✓ ✓ ✓ … ✓ ✕ const− ✓ ✓ ✓ … ✓ ✕ signed− ✓ ✓ ✓ … ✓ ✕ static− ✓ ✓ ✓ … ✓ ✕ unsigned− ✓ ✓ ✓ … ✓ ✕ extern− ✓ ✓ ✓ … ✓ ✕ Arithmetic Operations with Precedence +− ✓ ✓ ✓ … ✓ ✓ -− ✓ ✓ ✓ … ✓ ✓ *− ✓ ✓ ✓ … ✓ ✓ /− ✓ ✓ ✓ … ✓ ✓ %− ✓ ✓ ✓ … ✓ ✓ <<− ✓ ✓ ✓ … ✓ ✓ >>− ✓ ✓ ✓ … ✓ ✓ |− ✓ ✓ ✓ … ✓ ✓ &− ✓ ✓ ✓ … ✓ ✓ ^− ✓ ✓ ✓ … ✓ ✓ ~− ✓ ✓ ✓ … ✓ ✓ Using Integers − ✓ ✓ ✓ … ✓ ✓ Using Floating Point − ✓ ✓ ✓ … … ✕ Using Characters − ✓ ✓ ✓ … … ✕ Using Hex − ✓ ✓ ✓ … … ✓ Using Octal − ✓ ✓ ✓ … … ✓ Using Binary − ✓ ✓ ✓ … … ✓ Comperative Operations ==− ✓ ✓ ✓ … ✓ ✓ <=− ✓ ✓ ✓ … ✓ ✓ >=− ✓ ✓ ✓ … ✓ ✓ !=− ✓ ✓ ✓ … ✓ ✓ <− ✓ ✓ ✓ … ✓ ✓ >− ✓ ✓ ✓ … ✓ ✓ Branching If[2]− ✓ ✓ ✓ … ✓ ✓ Else If[2]− ✓ ✓ ✓ … ✓ ✓ Else[2]− ✓ ✓ ✓ … ✓ ✓ Switch− ✓ ✓ ✓ … ✓ ✓ Unary +− ✓ ✓ ✓ … … ✓ -− ✓ ✓ ✓ … … ✓ ++[3]− ✓ ✓ ✓ … ✓ ✓ --[3]− ✓ ✓ ✓ … ✓ ✓ !− ✓ ✓ ✓ … ✓ ✓ ~− ✓ ✓ ✓ … ✓ ✓ Casting − ✓ ✓ ✕ ✕ ✕ ✕ sizeof− ✓ ✕ ✕ ✕ ✕ ✕ Loops While[2]− ✓ ✓ ✓ … ✓ ✓ For[2]− ✓ ✓ ✓ … ✓ ✓ Do While[2]− ✓ ✓ ✓ … ✓ ✓ Jumps Return[1]− ✓ ✓ ✓ … ✓ ✓ Goto− ✓ ✓ ✓ … ✓ ✓ Break− ✓ ✓ ✓ … ✓ ✓ Continue− ✓ ✓ ✓ … ✓ ✓ Types auto− ✓ ✓ ✓ … ✓ ✕ long double− ✓ ✓ ✓ … ✓ ✕ double− ✓ ✓ ✓ … ✓ ✕ float− ✓ ✓ ✓ … ✓ ✕ long long int[4]− ✓ ✓ ✓ … ✓ ✕ long− ✓ ✓ ✓ … ✓ ✕ int− ✓ ✓ ✓ … ✓ ✓ short− ✓ ✓ ✓ … ✓ ✕ char− ✓ ✓ ✓ … ✓ ✕ void− ✓ ✓ ✓ … ✓ ✕ Immutable Strings − ✓ ✓ ✓ ✕ ✕ ✕ Preprocessor Directives #Warning✕ ✓ − − − − − #Include[5]✓ ✓ − − − − − #Define✓ ✓ − − − − − #Undef✕ ✓ − − − − − #If✕ ✓ − − − − − #Ifdef✕ ✓ − − − − − #Ifndef✕ ✓ − − − − − #Elif✕ ✓ − − − − − #Else✕ ✓ − − − − − #Endif✕ ✓ − − − − − #Pragma✕ ✓ − − − − − #Error✕ ✓ − − − − − #Line✕ ✓ − − − − − -
Symbol Legend
-
✓ The feature is fully implemented to the extent that we feel comfortable with it. ✕ The feature is not implemented and any functioning output it produces is purely coincidental. … The feature is thought to be implemented but not strictly verified. Support may be sporadic. − Feature has no use in this section. -
Optimization Algorithms Implemented
-
There are three different optimization levels implemented.
-O0(default),-O1, and-O2.-
-O0 - No optimization passes performed.
-
-O1 -
- Unreferenced Variables
- If, during the compilation process, the compiler recognices that there are variables declared, tempoary or not, that are only intialized and unused. It will try to remove them as a measure to try and reduce the number of instructions for a given program.
- Unreferenced Functions
- If, during the compilation process, the compiler recognices that there are functions declared and defined, that are unused. It will try to remove them as a measure to try and reduce the number of instructions for a given program.
-
-O2 -
- Constant Folding
- For expressions that require some sort of evaluation before the value can be used the compiler will try to evaluate the expression at compile time and replace the evaluation with the resultant value in the program.
- Constant Propagation
- Whenever a variable is referenced within the program, the compiler will try to replace the value of the variable with the known value of the variable wherever it deems it is safe to do so.
- IR Cleanup
-
Due to the nature of the IR, after the compiler iterates through the
IRLineobjects it will perform a local reference count of the variables within the operation and remove the ones that are deemed unnecessary.
-
-
Examples of C Programs and their Intermediate Representations
-
-
Arithmetic
-
int main() { int a = (1 + 2 + 3); int b = (56 * 78 * 5 / 20 - 3); int c = 56 % 2; int d = -10; int e = a&b; int f = a|b; int g = a^b; int h = ~a; int i = ~b; int j = ~c; int k = ~d; a = (j | a) - 97; b += (i + g) + 40; c -= (b + g) >> 12; d *= (j + c) - 25; e /= (c << -i) | 37; f %= (b | a) * 42; g <<= (-a >> b) ^ 19; h >>= (c / g) + 19; i |= (d ^ b) / 20; j &= (c + a) >> 12; k ^= (a % f) << 20; } -
Arithmetic_As_Function_Input
-
int function(int arithmetic_input) { return arithmetic_input; } int main() { int value_1 = function(1); } -
Assignment
-
int function() { return 1; } int main() { int a = 1; int b = 1 + 1; int c = function(); } -
Boolean
-
int main() { int one = 1; if (one) { } if (one > one) { } if (one < one) { } if (one == one) { } if (one != one) { } if (one >= one) { } if (one <= one) { } } -
Break
-
int main() { while(1) { break; } } -
For_Loops
-
int main() { int i = 0; for (i = 0; i < 10; i++) break; for (i = 0; i < 10; i++) { for (i = 0; i < 10; i++) { continue; } } for (i = 0; i < 10; i++) continue; for (i = 0; i < 10; i++) for (i = 0; i < 10; i++) { continue; } for (int j = 0; j == 0; j = j) { continue; } for (;;) continue; for (i = 0;;) continue; for (;1;) continue; for(;;i = i) continue; for (;;) {} } -
Functions_Strings
-
int return_strings(char string[], int i) { return 1; } int main() { int i = return_strings("test", 1); } -
Goto
-
int main() { goto label; int random_var = 0; label: } -
Identifiers_Variables_Functions
-
int test_function(int x, int y) { return 1; } int main() { int x = test_function(1, 1); return x; } -
If_Else
-
int main() { int i = 1; int j = 2; if (i > 0 && j < i){ } if (1) { } else if (0) { } else { if (1) { } } if (1) int a = 0; else int c = 2; } -
Initialization_Strings
-
int main() { char string[] = "test string"; char string_two[] = 'test string'; char string_special[] = "\n\t\\\'\"\%\$%&*$%&%*$&@@ __ +=-"; } -
Keywords
-
inline const unsigned int test() { return 10; } int main() { register int x; signed short t; const long rrr; volatile float qqq; static double aaa; unsigned int y = NULL; extern int q; } -
Pre_Processor
-
#include "../headers/test.h" #define FREE 500 int main() { return FREE; } -
Return
-
int function () {return;} int main () { int a; return 1; return function(); return 1+1; return (1+2); return a; } -
Switch
-
int main() { int i = 10; switch (i) { case 12: i--; break; case 11: i++; case 10: case 9: i++; int k; break; default: break; } return i; } -
Unary
-
int main() { int a = -10; int b = -a; int c = +a; if (!2) { } if (~2) { } } -
While
-
int main() { while(1) { int k; } do { int j; } while (1); while(2) break; }
-
-
Sub-modules
-
src.backend -
-
src.frontend -
-
src.optimizer -
-
src.run -
This module serves as the main interface to the compiler. It connects all the parts of the compiler in such a way that all representations are handed …